深度报告
下一个Agent:从Chatbot到主动学习机器
当前多数 Agent 只是带工具的聊天机器人,无长期记忆、无法积累成长。真正的 Agent 2.0 是进化式系统,核心在上下文工程,能实现多层次记忆与知识沉淀复用,这场系统工程升级才刚起步。
分类
深度报告
发布日期
2026-02-09
阅读时间
6 分钟阅读
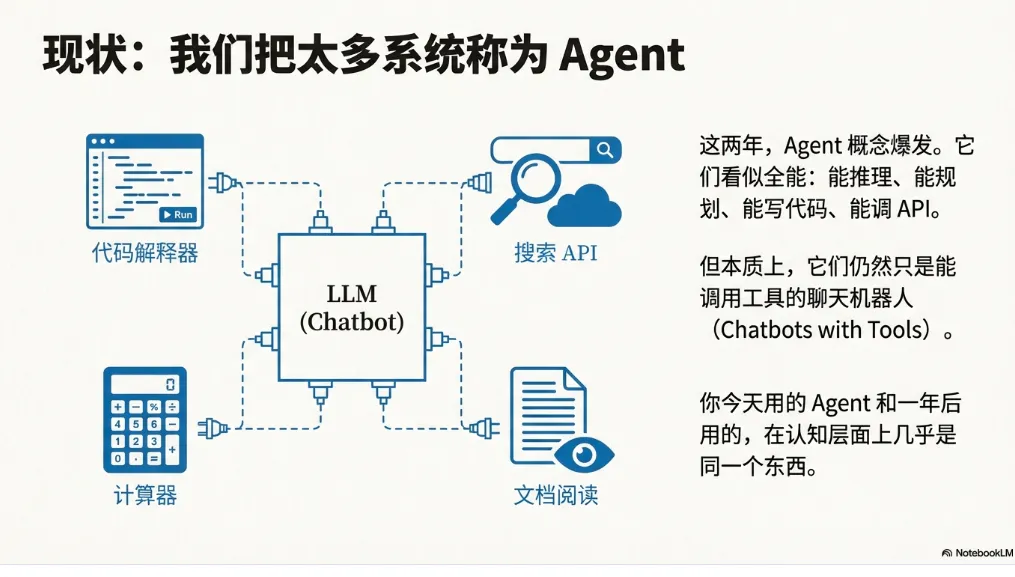
这两年,我们把越来越多的系统称为 Agent。
但说实话,大多数所谓的 Agent,本质上仍然只是能调用工具的聊天机器人。
它们能推理、能规划、能执行任务。它们能写代码、做分析、调 API、生成内容。
看起来很聪明。但它们有一个致命问题:它们不会变得更聪明。
你今天用的 agent和你一年后用的 agent,在认知层面上几乎是同一个东西。
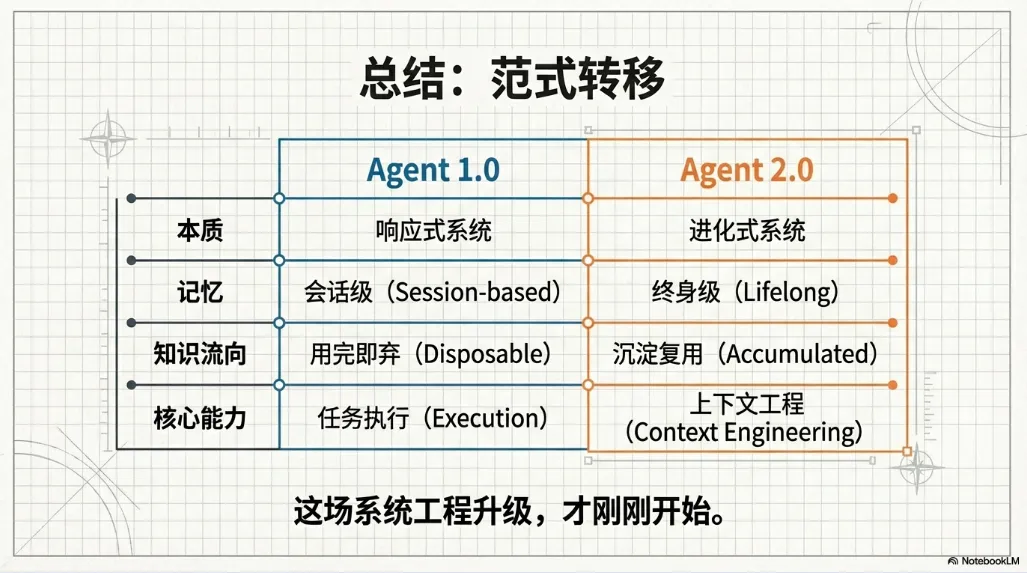
Agent 1.0 的本质:一次性智能
当前主流的 Agent,都是响应式系统:
输入 → 推理 → 输出 → 结束。
哪怕加上了对话历史,它们也只是在当前会话里短暂“记得”你说过什么。一旦 session 结束,一切归零。
这带来的后果是:
• 你纠正过它的判断?下次还会再犯 • 你反复表达过偏好?它每次都重新猜 • 团队里有人教会它一个重要经验?只对那一次对话有效 • 它在真实业务中“悟到”一个关键洞察?用完就消失了
这不是“模型不够聪明”。这是系统结构决定的遗忘。而人类组织真正有价值的东西,恰恰不是单次回答,而是——经验、判断、隐性知识、集体记忆。
那个让我真正想清楚的瞬间
我们在内部测试一种新范式时,有一个场景让我意识到:Agent 的关键跃迁,不在模型,而在“是否能学习”。
一次对话中,一位特赞的客户负责人和系统讨论一个看似局部的问题:
为什么客户产出很多内容,但转化始终上不去。系统在分析内容资产结构、分发路径和历史数据后,给出了建议,同时把一个判断沉淀下来:在很多组织里,问题并不出在“内容不够好”,而是用户理解被割裂在不同部门、不同工具、不同视角之中。
几天后,另一位完全不同角色的同事,在另一段对话里,咨询的是新品定价与市场验证。
系统在给出 A/B 定价模拟和用户反馈预测的同时,主动提醒:某些定价假设,实际上建立在对用户认知的误判之上——而这些误判,正是团队此前在内容和调研中反复遇到、但从未被系统性复用的经验。
没有人显式告诉它“把这两次对话连起来”。没有共享 briefing。也没有人为交接。一个人和系统互动中形成的判断,被另一个人在完全不同的业务问题中,直接继承并放大。
一个人教会系统的经验,被另一个人直接复用。
那一刻我意识到:这才是我们真正想要的 Agent。
Agent 2.0:不是更会回答,而是会“积累”
真正的 Agent 2.0,必须满足一个条件:
第 1000 次交互的系统,必须比第 1 次更好。
这种“更好”,不是语气更像人,而是判断更稳、建议更贴近现实、错误更少、上下文更完整。
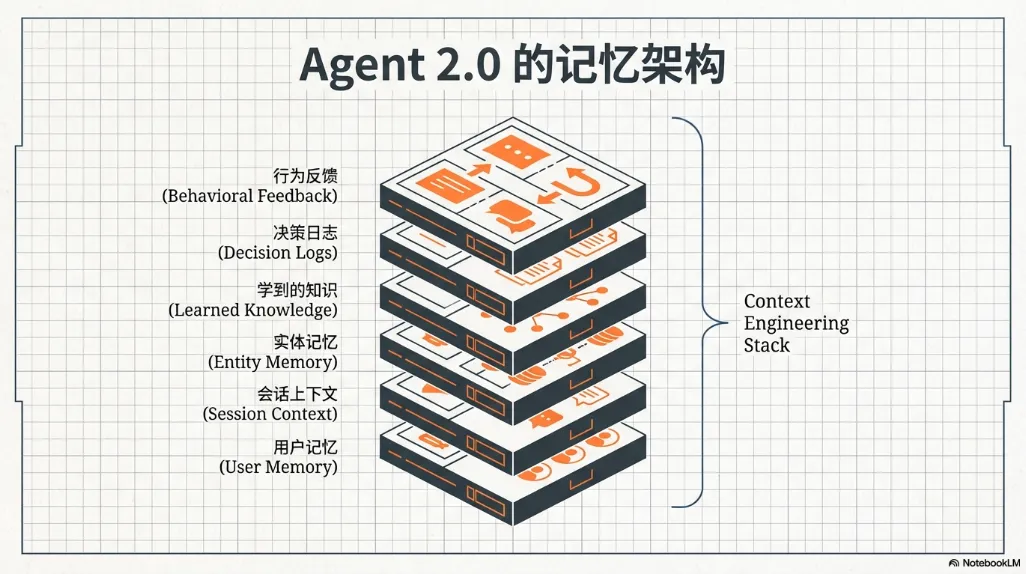
要做到这一点,Agent 必须具备多层次的学习与记忆能力:
• 用户记忆:长期偏好、背景、沟通方式 • 会话上下文:目标、进度、阶段性决策 • 实体记忆:公司、产品、行业、组织结构 • 学到的知识:跨对话沉淀的经验与模式 • 决策日志:为什么当时这么判断 • 行为反馈:什么有效,什么被否定
这些东西,本质上都不是模型参数。它们是上下文结构。
这不是智能问题,而是上下文工程问题
今天的大模型,已经足够聪明。Agent 2.0 不是一次认知突破,而是一次系统工程升级。
问题不在于“能不能推理”,而在于:
• 这些推理有没有被保存? • 有没有被结构化? • 能不能在未来被再次调用? • 能不能跨人、跨场景、跨时间复用?
如果没有一个稳定、可演化的上下文系统,Agent 永远只能停留在 1.0。
Agent 的下一步,不是更会聊天,而是拥有记忆、判断与组织经验的数字生命体。
这场升级,才刚刚开始。请大家拭目以待我们的实践!
分类
深度报告
发布日期
2026-02-09
阅读时间
6 分钟阅读
相关推荐

AI Native 组织,第一步从哪开始?

AI Native CEO 的选择:雇个GEA管团队,盯住机会
