AI太自信,但全是幻觉?如何破解企业级AI的ROI难题
企业 AI 常因高智能低上下文陷入 “自信幻觉”,ROI 低迷。特赞 GEA 通过构建 Context Layer,统一术语、编码规则、映射关系、记忆决策,快速沉淀企业专属上下文,让 AI 一周内具备资深员工水平,破解 ROI 难题。

AI的性能指标在飙升——推理能力从5%到87.5%,大学考试从35%到87%。
但56%的CEO报告AI投资零回报。只有20%感受到显著价值。甚至使用AI工具的开发者,工作速度反而下降了19%。
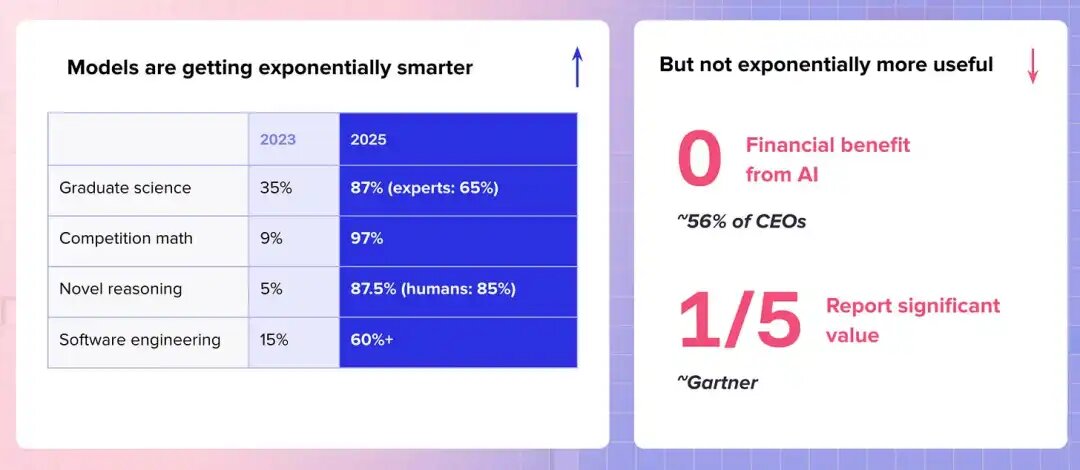
看似矛盾,但问题很清楚:模型变聪慧了,回报没跟上。
认知科学的发现很简单:IQ只决定工作表现的10%。最好的员工不一定最聪慧,而是对这里怎么实际运转了解最深的人。TA知道:
客户的真实需求,不只是表面需求
哪些规则可以打破,什么时候应该打破
上次犯过的错误,这次怎样避免
决定表现/结果好不好的,恰恰就是“上下文”。
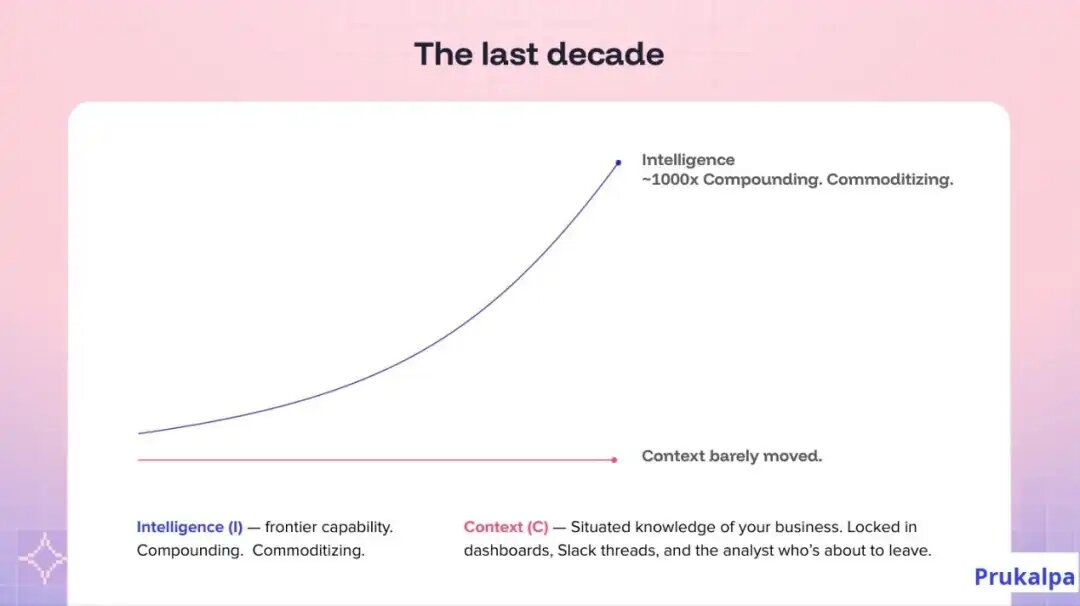
然而过去十年,智能和上下文的差距在扩大。你可以按API价格购买Intelligence——每家企业都可以轻松获得智能,但Context必须在组织内部一点点积累。

Context 是如何积累的?这里有一个形象的案例:
Maya在芝加哥做客服。
一通电话:愤怒的母亲,孩子接触到过敏原。Maya在90秒内化解了冲突、处理了退款、阻止了社媒负面评价,获得五星好评。
Maya需要的是什么?四个月积累的Context:
1. 规则知识 —— 过敏原政策、退款流程
2. 判断力 —— 何时道歉够了,何时需要补偿
3. 情景理解 —— 这是首次客户还是投诉十七次的老客
4. 系统理解 —— 这是分店的系统问题还是一次事件
没有任何一条是天生的。通过文档、培训、学习资深员工、在监督下犯错、被纠正,她逐步建立了这套能力。
这正是如今企业AI面临的问题。
现状:企业的AI像Maya的第一天
你部署的每个AI agent都有Maya四个月才积累到的智能,但它对你的业务却一无所知。它不知道:
你们说"收入"时的准确定义
"已解决"投诉的标准
那些例外规则
客户的历史
每次部署都是从零开始,并且永远不会成长。如果用两个轴来看:Intelligence(纵轴)和Context(横轴)。
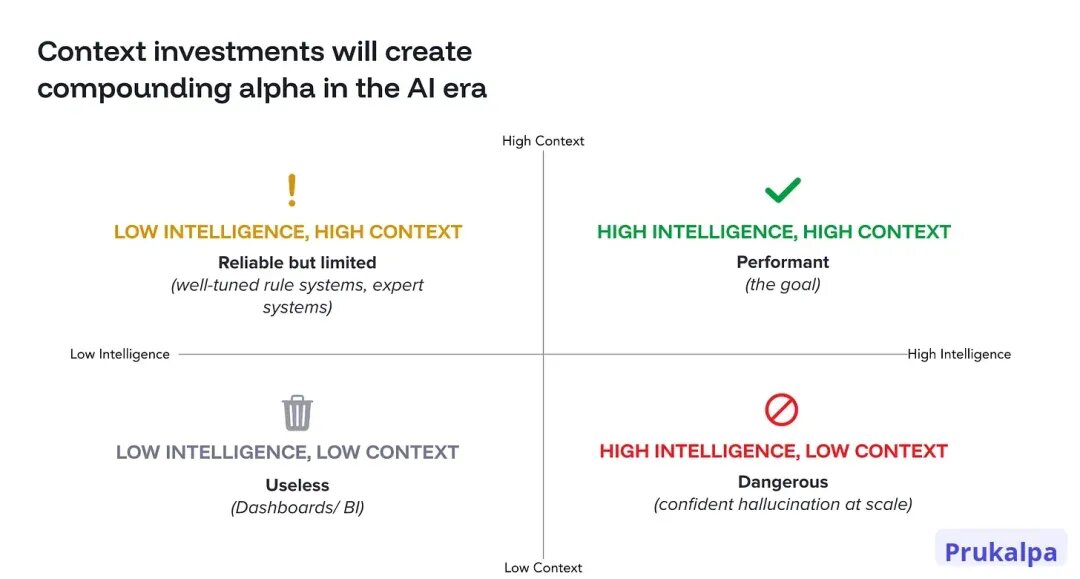
大多数企业的AI在右下象限:高智能、低Context。
问题是什么——输出自信、清晰、经常是错的。最危险的是,那些错误的输出却有理有据。“自信的幻觉” 在规模上运行,把AI从潜在资产变成负债。
解决方法不是买更好的模型。而是构建另一个轴——Context 业务上下文。
企业在构建Context时,遇到的三重困境
1、部署容易,Context构建很难
内部署agent、添加业务Context需要五个月。因为你部署时才意识到agent对你的业务有多陌生。
2、Agent之间没有记忆共享
每部署一个新agent,都要重新积累一遍。Agent A被纠正,Agent B不知道。第十个agent对你业务的了解和第一个一样陌生。
3、多Agent语义冲突
Agent A的"收入"是已成交订单。Agent B的"收入"是已确认收入。独立看都合理,但当它们协作时,冲突就暴露了。财务团队最后要白白耗费一周协调数据差异,而不是做财务工作。
如何解决这个难题?
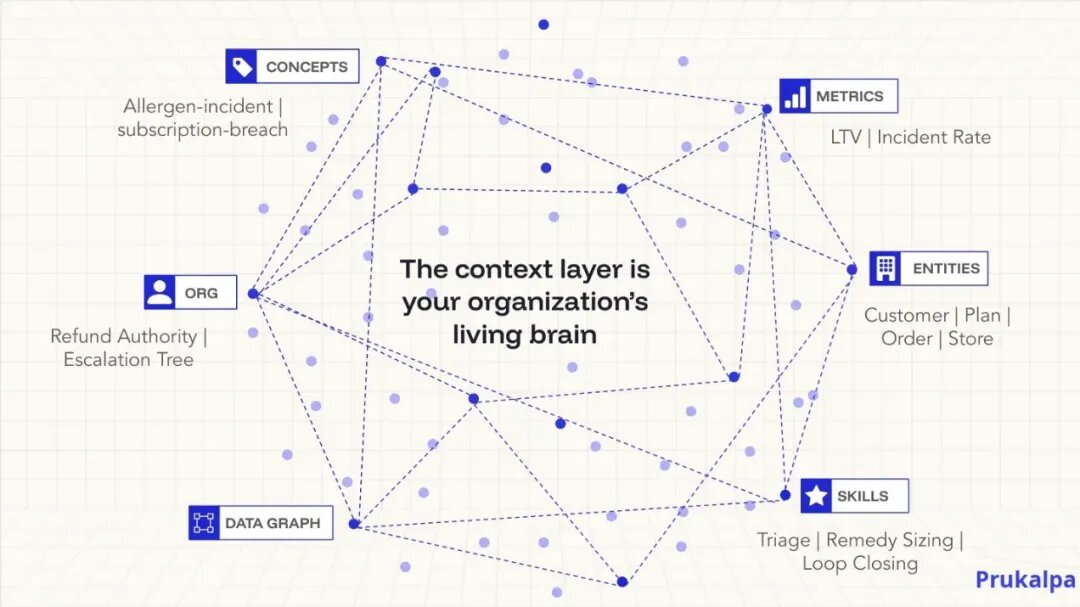
GEA的Context Layer正是为了解决这一问题。GEA 通过构建企业的Context Layer,让AI从Day 1变成资深员工。具体包括:
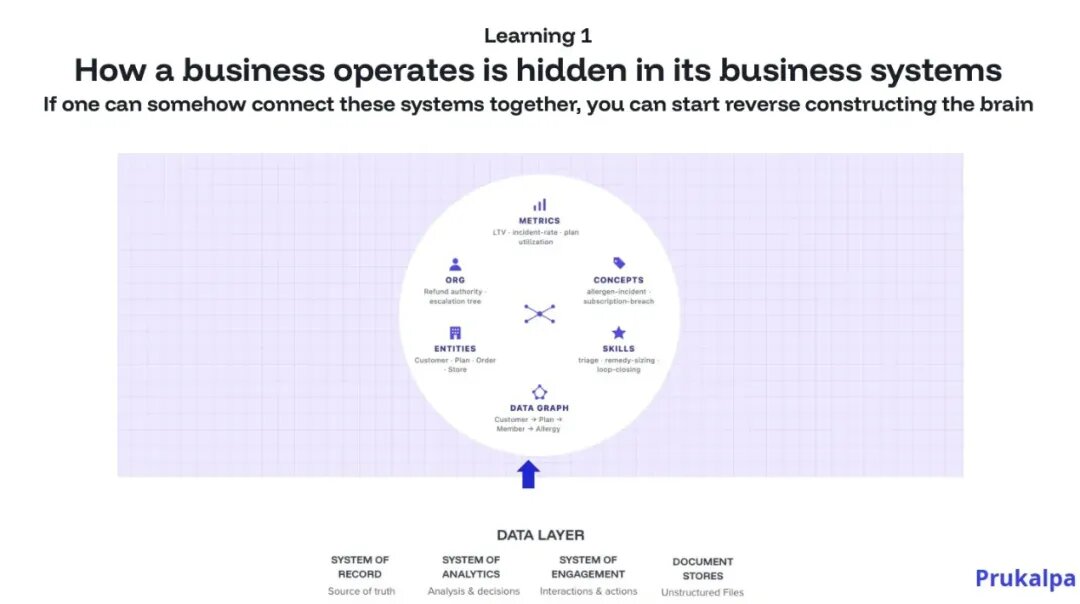
术语统一 —— "活跃客户"在营销和财务部门可能有不同定义。GEA的Context Layer不是强行同步,而是记录定义、应用场景、何时例外。
规则编码 —— 那些隐性规则(支持政策的三个例外、特殊客户的处理方式)存在员工脑中。GEA通过读取既有系统(SQL、数据治理文档、历史决策),快速识别和编码这些规则。
关系映射 —— CRM中的"客户"、数据仓库的"账户"、ERP的"联系人"其实是同一个东西。GEA维持这个一致性,让所有agents看到统一的企业模型。
决策记忆 —— 每次agent运行、人类审查,都产生信号。批准是数据,纠正是数据。GEA捕获这些信号,系统每次运行都在加强对企业的理解。这不是一次性配置,而是自学习。
由此,带来了四个关键转变
1. 既有知识快速激活
企业的运营方式已经被编码在系统里:数据仓库血统编码了依赖关系,SQL编码了业务逻辑,治理文档编码了语义意图。GEA可以读取这些,综合它们,用几小时生成企业语义地图的初稿。而不是原来的几个月。Context构建从手工变成自动化。
2. Context质量呈指数级增长
AI生成初稿 → 人工精炼 → AI基于精炼版继续生成 → 质量不断上升。数据表明:AI生成的Context(经人类验证),最终质量往往超过人类从零开始写的。因为AI看到整个图,人类只看一个字段。这是飞轮,不是一次性项目。
3. 交互产生Context
每次AI在生产环境运行、人类审查输出时,都产生有价值的信号。批准是数据,纠正是数据,"这不是我们的做法"是数据。大多数企业让这些信号白白浪费了。GEA会捕获它们,让它们回流到Context Layer中,构建外部公司无法复制的优势。
4. Context需要生命周期管理
Context会失效。业务在变化——定义被更新,产品线被重构。GEA的Context Layer需要像代码库一样被维护:版本化、测试、治理。一旦做到这一点,企业就拥有了真正可持续运行的AI决策系统。
企业的智慧,如何被真正激活
企业现在面临两条路:继续部署聪慧但无Context的AI,结果是自信的幻觉在公司大规模运行,或者,着手构建Context Layer——让AI拥有企业的实际知识、潜规则、决策标准。
这不需要从零发明。这些知识已经被编码在企业的系统里,只是没人系统地读过。GEA的Context Layer做的正是把这些散落的知识变成AI可以调用的、持续演进的组织记忆。
一个全球食品集团在GEA上的实践表明:系统可以在72小时内识别8000个业务概念、500条隐性规则。新部署的AI agent不需要五个月才能达标,可以在一周内就具备资深员工的表现水平。
这是AI投资的拐点:从亏损到回报。
不是因为模型变聪慧了,而是企业终于给了它足够的上下文。
分类
深度报告
发布日期
2026-05-28
阅读时间
9 分钟阅读
分享本页
相关推荐

AI 能自己工作了,谁在管理它?企业级AI的Harness工程

AI Native了,然后呢?谈谈这个时代的品牌和好品味
